- Einleitung
Wer sich mit der Absicherung von Webapplikationen beschäftigt, stößt zwangsläufig auf sogenannte Web Application Firewalls (WAF). Sie gelten als zentrale Verteidigungskomponente gegen Angriffe wie SQL Injection, Cross-Site Scripting oder Remote Code Execution und werden von Unternehmen unterschiedlichster Größenordnungen eingesetzt. Häufig entsteht dabei der Eindruck, dass mit ihrem Einsatz ein wesentlicher Teil der Sicherheitsanforderungen bereits abgedeckt ist.
Dieses Vertrauen kann jedoch trügerisch sein. Eine WAF fungiert im Kern als Filtersystem, das eingehenden HTTP-Traffic anhand definierter Regeln, Signaturen und heuristischer Verfahren analysiert und potenziell schädliche Anfragen blockiert. Angreifer sind mit diesen Mechanismen jedoch vertraut und haben im Laufe der Zeit vielfältige Techniken entwickelt, um entsprechende Schutzmaßnahmen zu umgehen. Dazu zählen unter anderem die gezielte Manipulation von Zeichenkodierungen, das Ausnutzen von Unterschieden in der Interpretation zwischen WAF und Backend-Systemen sowie Ansätze, bei denen der Schutz auf struktureller Ebene umgangen wird.
Im weiteren Verlauf werden sowohl klassische Umgehungstechniken auf String-Ebene als auch alternative Ansätze betrachtet, bei denen eine WAF auf Systemebene umgangen wird. Ziel ist es dabei nicht, konkrete Angriffsanleitungen zu vermitteln, sondern ein fundiertes Verständnis für die Grenzen solcher Schutzmechanismen zu schaffen. Nur durch das Verständnis potenzieller Schwachstellen lassen sich Sicherheitsmaßnahmen nachhaltig verbessern.
- Funktionsweise WAF
Bevor mögliche Umgehungstechniken betrachtet werden, ist es sinnvoll, zunächst die grundlegende Funktionsweise einer Web Application Firewall zu verstehen.
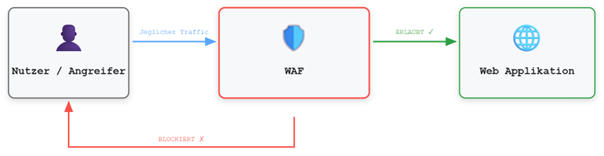
Eine WAF fungiert als vorgelagerte Schutzschicht zwischen Client und Webapplikation. Sämtliche eingehenden HTTP-Anfragen passieren diese Instanz, bevor sie das Backend erreichen. Dabei werden verschiedene Bestandteile der Requests analysiert, darunter URL, Query-Parameter, Header, Cookies sowie der Request Body. Diese werden mit einem definierten Regelwerk abgeglichen, das auf Signaturen und heuristischen Verfahren basiert. Wird ein Muster erkannt, das auf einen potenziellen Angriff hindeutet, blockiert die WAF die entsprechende Anfrage, bevor sie die eigentliche Applikation erreicht.
Dieses Prinzip lässt sich vereinfacht als vorgeschalteter Filtermechanismus darstellen:
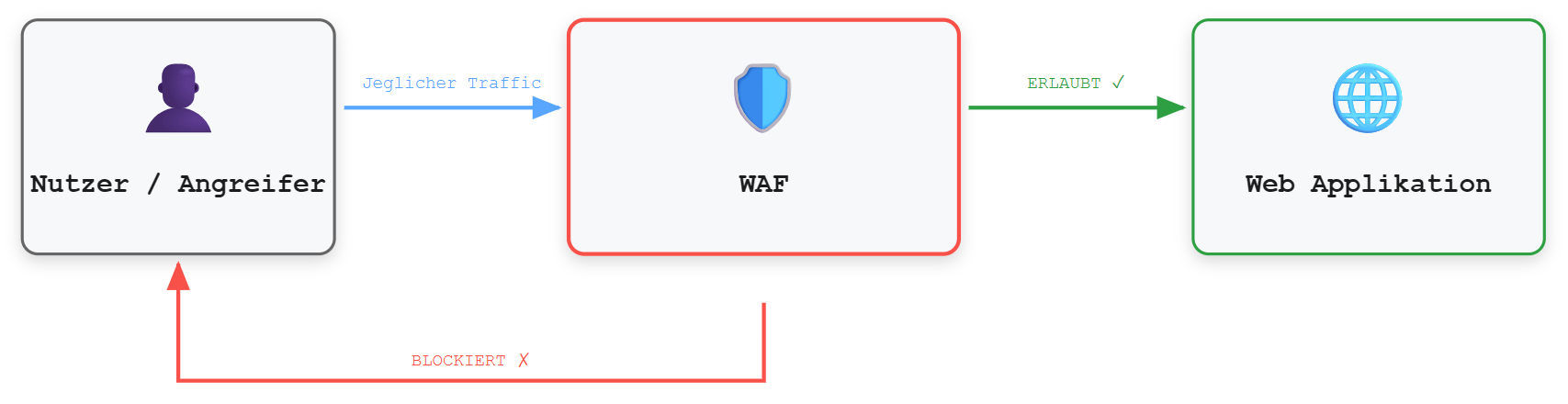
Die meisten WAF-Lösungen kombinieren mehrere Erkennungsansätze. Ein zentraler Mechanismus ist die signaturbasierte Erkennung, bei der eingehende Anfragen mit einer Datenbank bekannter Angriffsmuster abgeglichen werden. Typische Beispiele sind Regeln, die nach Zeichenketten wie UNION SELECT oder <script> suchen. Dieser Ansatz ist effizient und zuverlässig bei bekannten Angriffen, verliert jedoch an Wirksamkeit, sobald entsprechende Muster geringfügig verändert werden.
Ergänzend dazu kommen häufig regelbasierte heuristische Verfahren zum Einsatz, die nicht auf exakte Zeichenfolgen angewiesen sind, sondern verdächtige Strukturen und Kombinationen identifizieren. Moderne WAFs nutzen darüber hinaus oft Scoring-Modelle, wie beispielsweise das OWASP Core Rule Set für ModSecurity. Dabei werden einzelnen Auffälligkeiten Punkte zugewiesen, und eine Anfrage wird erst dann blockiert, wenn ein definierter Schwellenwert überschritten wird.
Ein wesentlicher, häufig unterschätzter Aspekt besteht darin, dass eine WAF ihre Entscheidungen auf Grundlage ihrer eigenen Interpretation einer Anfrage trifft. Diese Interpretation kann sich jedoch von der Verarbeitung durch das Backend-System unterscheiden. Genau diese Diskrepanz zwischen Parser und Interpreter bildet die Grundlage vieler klassischer Umgehungstechniken. Darüber hinaus existieren Ansätze, bei denen die WAF nicht auf Ebene einzelner Anfragen, sondern auf Systemebene umgangen wird. Beide Perspektiven werden im Folgenden detailliert betrachtet.
- Arten von WAFs
Web Application Firewalls können in unterschiedlichen Architekturen implementiert werden, die jeweils spezifische Vor- und Nachteile aufweisen:
Netzwerkbasiert
Netzwerkbasierte WAFs werden typischerweise als dedizierte Hardware-Appliances im eigenen Rechenzentrum betrieben und direkt vor den Webservern positioniert. Sie zeichnen sich durch eine hohe Performance aus, da die Filtermechanismen auf spezialisierter Hardware ausgeführt werden. Demgegenüber stehen hohe Anschaffungs- und Wartungskosten.
Hostbasiert
Bei hostbasierten WAFs erfolgt die Integration direkt auf dem Zielsystem, beispielsweise durch den Einsatz von ModSecurity in Kombination mit Nginx oder Apache. Diese Variante bietet ein hohes Maß an Flexibilität, da Regeln individuell und granular auf die jeweilige Anwendung abgestimmt werden können. Zudem ist eine vollständige Analyse des Datenverkehrs inklusive entschlüsseltem HTTPS möglich. Allerdings geht dies mit einem erhöhten Ressourcenverbrauch einher.
Cloudbasiert
Cloudbasierte WAFs werden von externen Dienstleistern wie Cloudflare, AWS oder Akamai bereitgestellt. Der gesamte Datenverkehr wird über die Infrastruktur des Anbieters geleitet und dort gefiltert. Diese Lösung ist in der Regel schnell implementierbar und erfordert keinen eigenen Hardwarebetrieb. Gleichzeitig bedeutet sie jedoch, dass der gesamte Internetverkehr über einen Drittanbieter abgewickelt wird, was insbesondere aus Datenschutz- und Kontrollperspektive berücksichtigt werden muss.
- Bypasses
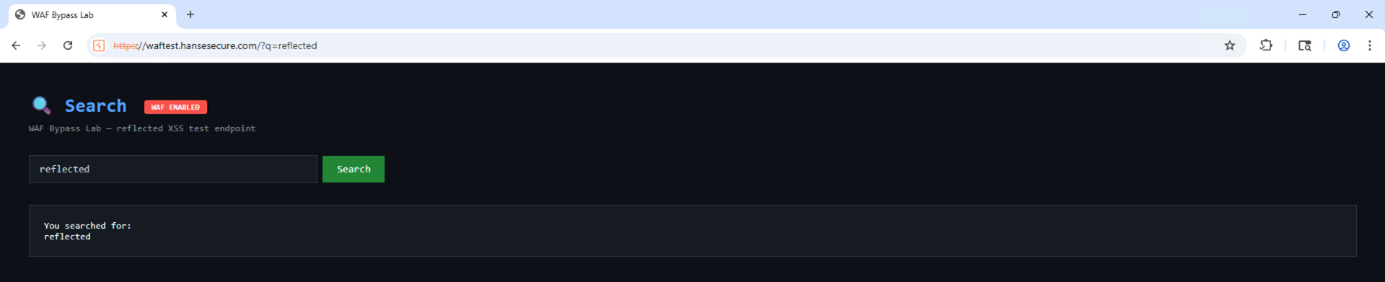
Zur Veranschaulichung der Funktionsweise einer WAF sowie möglicher Umgehungsansätze wurde eine einfache Webapplikation aufgebaut, die für reflektiertes Cross-Site Scripting anfällig ist:

Der String nach dem gesucht wird, wird auf der Seite reflektiert:
Die Applikation wird jedoch hinter einer WAF betrieben, wodurch ein klassischer Payload wie <script>alert(1)</script> bereits zuverlässig blockiert wird:
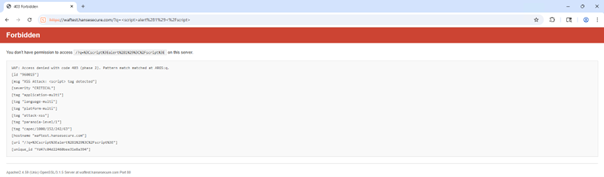
Damit ist die Ausgangssituation definiert: eine für XSS anfällige Webapplikation sowie eine vorgeschaltete WAF, deren Schutzmechanismen umgangen werden sollen. Da WAFs mit einer Vielzahl unterschiedlicher Filter arbeiten, die den Inhalt eingehender Requests auf bestimmte Muster prüfen, besteht ein naheliegender erster Ansatz darin, den Payload so zu verändern, dass er von diesen Mechanismen nicht erkannt wird. Dies kann beispielsweise durch Kodierung, Obfuskation oder andere Modifikationen erfolgen.
Zu den klassischen Methoden zählen unter anderem:
- URL- oder HTML-Encoding
- Variation von Groß- und Kleinschreibung
- Einfügen von Newline- oder Whitespace-Zeichen
- Verwendung alternativer Funktionen oder Tags
- String-Verkettung
- weitere vergleichbare Techniken
Im vorliegenden Beispiel könnte die WAF etwa durch einen entsprechend veränderten Payload umgangen werden:
<svg onpointerover=window[‘ale’+’rt’](1)>
Durch die Verwendung eines alternativen HTML- beziehungsweise SVG-Kontexts in Kombination mit der Aufspaltung des Funktionsnamens wird die Erkennung durch einfache signaturbasierte Filter erschwert. Solche Mechanismen zielen häufig auf bekannte und eindeutig erkennbare Muster ab, können jedoch an Wirksamkeit verlieren, wenn diese durch syntaktische Variationen oder Obfuskation verändert werden. So könnte die WAF beispielsweise umgangen werden:

Ein weiterer möglicher Payload wäre der Folgende:
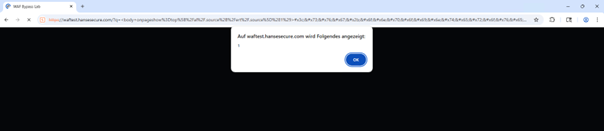
<body onpageshow=top[/al/.source+/ert/.source](1)>
Hier wird das Stichwort “alert“ durch das Zusammensetzen von Regex-Ausdrücken erstellt (/al/.source ergibt „al“):
Zu dieser Kategorie von WAF-Bypasses existiert bereits eine Vielzahl an Veröffentlichungen und weiterführenden Informationen, weshalb an dieser Stelle nicht näher darauf eingegangen wird.
Stattdessen wird im Folgenden ein alternativer Ansatz betrachtet, bei dem der Schutzmechanismus nicht auf Ebene einzelner Requests umgangen wird, sondern strukturell. Voraussetzung hierfür ist ein grundlegendes Verständnis der Funktionsweise einer WAF auf Systemebene. Eine WAF ist typischerweise zwischen Client beziehungsweise potenziellem Angreifer und der Webapplikation positioniert. Sämtlicher Datenverkehr wird über diese Instanz geleitet und muss die dort implementierten Prüfmechanismen passieren, bevor eine Weiterleitung an das eigentliche Zielsystem erfolgt.
Zur Einordnung kann auf die zuvor dargestellte Architektur zurückgegriffen werden:
Vor diesem Hintergrund stellt sich die Frage, welche Auswirkungen es hätte, wenn die WAF nicht durch gezielte Modifikation von Request-Inhalten umgangen wird, sondern vollständig auf struktureller Ebene. In einem solchen Szenario würde der Datenverkehr die Schutzinstanz nicht mehr durchlaufen, sodass keine Filterung oder Analyse mehr stattfindet. Das resultierende Verhalten lässt sich wie folgt veranschaulichen:
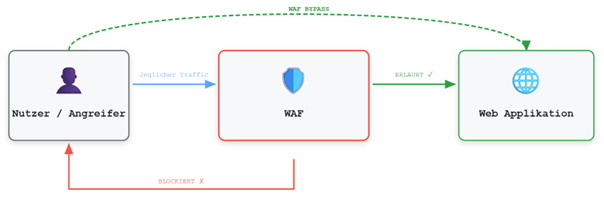
In einem solchen Szenario könnten beliebige Payloads ohne Einschränkung verarbeitet werden. Darüber hinaus würden auch Schutzmechanismen wie Rate Limiting, die durch die WAF implementiert sind, nicht mehr greifen.
Ein entsprechender Ansatz zur Umgehung basiert auf der Frage, wie der Datenverkehr überhaupt über die WAF geleitet wird. Ein zentraler Faktor hierbei ist die DNS-Konfiguration der Webapplikation. Der DNS-Eintrag legt fest, an welche Zieladresse ein Client seine Anfragen sendet, wenn eine bestimmte Domain oder Subdomain aufgerufen wird.
In der Praxis sieht ein DNS-Eintrag so aus:

Für diesen Anwendungsfall wurde die DNS-Konfiguration so gewählt, dass sämtliche Anfragen an waftest.hansesecure.com auf eine definierte IP-Adresse zeigen. Auf dieser Adresse ist die WAF an den Ports 80 und 443 erreichbar, analysiert eingehende Requests und leitet ausschließlich als legitim bewerteten Traffic an die eigentliche Webapplikation weiter.
Soll die Applikation direkt angesprochen werden, also unter Umgehung der WAF, ist es erforderlich, die tatsächliche Zieladresse des Backend-Systems zu kennen. Hierzu zählen insbesondere die IP-Adresse und gegebenenfalls der verwendete Port. Anschließend kann ein Client so konfiguriert werden, dass die Namensauflösung über DNS umgangen und stattdessen direkt die entsprechende Zieladresse verwendet wird.
Eine zentrale Herausforderung besteht darin, diese Informationen zu ermitteln, da die eigentliche Infrastruktur in der Regel hinter einer WAF und häufig zusätzlich hinter einem Reverse Proxy verborgen ist. Ein möglicher Ansatzpunkt ist die Auswertung öffentlich verfügbarer Registrierungsdatenbanken. Für den europäischen Raum, den Nahen Osten sowie Teile Zentralasiens stellt die RIPE-Datenbank entsprechende Informationen bereit, darunter auch registrierte IP-Adressbereiche von Organisationen.
Im ersten Schritt kann daher eine Recherche anhand des Unternehmensnamens erfolgen, um zugehörige IP-Adressbereiche zu identifizieren. Hierfür bietet sich insbesondere die Volltextsuche der RIPE-Datenbank an (https://apps.db.ripe.net/db-web-ui/fulltextsearch).
Werden auf diesem Weg ein oder mehrere IP-Adressbereiche identifiziert, kann darauf aufbauend ein entsprechender Umgehungsversuch erfolgen. Zunächst ist es erforderlich, eine vollständige Liste der dem Unternehmen zugeordneten IP-Adressen zu erstellen. Anschließend gilt es zu ermitteln, auf welcher dieser Adressen die relevante Webapplikation betrieben wird.
Ein möglicher Ansatz besteht darin, die identifizierten Systeme gezielt darauf zu prüfen, ob sie auf den Host-Header der untersuchten Webapplikation reagieren. Liefert ein System bei entsprechend gesetztem Host-Header eine Antwort, die mit der der eigentlichen Applikation übereinstimmt, kann dies ein Hinweis darauf sein, dass es sich um das zugrunde liegende Backend-System handelt.
Achtung: Dabei ist zu beachten, dass die Aussagekraft dieses Verfahrens stark von der jeweiligen Webserver-Konfiguration abhängt. In manchen Fällen reagieren Systeme auch bei einem nicht passenden Host-Header mit einer regulären Antwort, wodurch die Ergebnisse verfälscht werden können.
Für eine solche Überprüfung bietet sich ein automatisierter Vergleichsansatz an. Dabei wird zunächst eine Referenzantwort der regulären Webapplikation erhoben, um anschließend zu prüfen, ob identifizierte Zielsysteme in ihrem Antwortverhalten mit dieser Referenz übereinstimmen. Als Vergleichsbasis sollte dabei möglichst eine statische oder konsistente Ressource verwendet werden, um Abweichungen zuverlässig erkennen zu können. Konkret sollte ein Skript genutzt werden, welches die folgenden Arbeitsschritte durchläuft:
- Initialer Request an die Webapplikation über die originale Domäne & Abspeichern der Antwort
Hinweis: hier sollte der Request an eine Seite wie /index.html o.ä. erfolgen, um einen Vergleich für die Zukünftigen Anfragen zu haben
Beispiel: GET-Anfrage an waftest.hansesecure.com/index.html
- Überprüfung jeder einzelnen IP-Adresse, indem die Domäne mit der jeweiligen IP-Adresse ausgetauscht wird
Beispiel: GET-Anfrage an <IP>/index.html
- Wenn hier nun eine erfolgreiche Rückmeldung kommt und die Antwort auch der Antwort aus Schritt 1 gleicht, haben wir den richtigen Server gefunden
Zeigt ein System im weiteren Verlauf ein Antwortverhalten, das mit der zuvor erhobenen Referenz übereinstimmt, kann dies auf eine technische Verbindung zur untersuchten Applikation hindeuten. Die Ergebnisse sind jedoch stets im Kontext der konkreten Infrastruktur und Konfiguration zu bewerten und erlauben nicht zwangsläufig eine eindeutige Zuordnung.
Wird auf diesem Weg das zugrunde liegende Zielsystem identifiziert, kann im nächsten Schritt die direkte Kommunikation mit diesem System konfiguriert werden. Ziel ist es dabei, die Namensauflösung über DNS zu umgehen und stattdessen eine feste Zuordnung zwischen Domain und IP-Adresse zu erzwingen.
Dies lässt sich über die lokale Hosts-Datei realisieren. Durch einen entsprechenden Eintrag wird festgelegt, dass Anfragen an eine bestimmte Domain nicht mehr über den regulären DNS-Prozess aufgelöst, sondern direkt an eine definierte IP-Adresse gesendet werden.
Unter Windows befindet sich die Hosts-Datei standardmäßig unter C:\Windows\System32\drivers\etc\hosts und muss mit administrativen Rechten bearbeitet werden. Am Ende der Datei kann ein Eintrag im folgenden Format ergänzt werden:
<IP-Adresse> <Hostname>
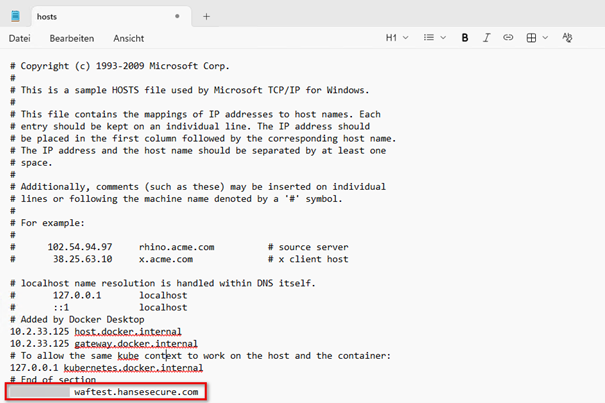
Im beschriebenen Beispiel würde die Domain somit direkt auf die zuvor identifizierte Zieladresse zeigen.
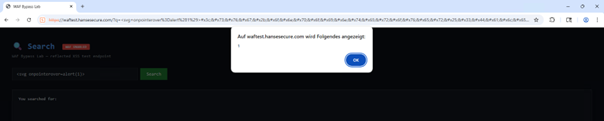
Nach dem Speichern der Anpassung werden Anfragen des Clients an die entsprechende Domain direkt an die definierte IP-Adresse geleitet. Dadurch erfolgt die Kommunikation unter einer Umgehung der ursprünglich vorgeschalteten Instanz, sodass keine zusätzliche Filterung oder Analyse des Datenverkehrs durch diese Komponente stattfindet. Auf diesem Weg kann der Payload <script>alert(1)</script> ungehindert zu reflektiertem Cross Site Scripting führen:
- Fazit
Der dargestellte Ansatz zeigt eine alternative Perspektive auf die Umgehung von WAF-Mechanismen und verdeutlicht, dass Schutzmaßnahmen stets im Kontext der gesamten Infrastruktur betrachtet werden müssen. Auch wenn diese Technik nicht in jedem Szenario anwendbar ist, stellt sie dennoch einen relevanten Ansatz dar, der die Grenzen solcher Sicherheitsmechanismen aufzeigt und zur weiterführenden Analyse anregen kann.


